






The Next Wave in Productivity Tools – Web Office extremely good and detailed article on the next generation!
Blogroll
reBlogger Screens
How dependant on search are you?
April 28, 2006 — Mark WilsonI learned so much from this post: How much do you Google? Looking at the details, the calendar, the graphs… it's amazing. The stats will be similar for me. I know that Google tracks searches (if I login) but I had no real concept of how much I google each day.
New Interface – going stealth to protect the IP
April 28, 2006 — Mark WilsonAfter poking our head up a bit in the Coding reBlogger blog (and on Flikr) we've decided to go stealth. I'll keep blogging, but Ivan's work will no longer be public.
We've always thought we were onto something big and we began building it. As we built it, we refined it and discovered we were onto something even bigger.
We've begun to see that it has the potential to significantly shake the web. It should change the nature of:
- hyperlinking
- tagging
- commenting
- user generated content
It's an evolutionary shift in the nature of the web. Evolutionary, not revolutionary… but it will be so pervasive that it will be rapildy included into more and more products. As it's use becomes widespread, it will force new extensions to the HTTP spec.
Some would think that developing this stuff in public will create buzz and that's good for our company, but I've realized that we need to be a bit more strategic and protect what we have invented.
We are now approaching what we're building in two parts:
- the products – reBlogger, reNNTP, various websites – which will use the new interface
- the IP – which has tremendous potential in itself as intellectual property/patents.
I have no doubt our IP will be bought out and I am planning for it. Possible buyers of the IP/patent include Microsoft, Technorati, WordPress and any other cashed-up blog-related IP company.
Why take this approach? It's simply because we don't have the ability to shepherd the idea, shape the IP and help with implementations.

Next generation of Talk Digger
April 27, 2006 — Mark WilsonAnother heads up: Some screenshots of the next generation of Talk Digger. Read the full post or just check out the screenshots below of the upcoming improvements to Talk Digger (blog)


Feeding on Pheedo
April 27, 2006 — Mark WilsonOne of the signals I look for in a company that will eventually have ongoing and lasting success is this: they keep on pumping out changes, improvements, innovations and products. They don't stop. One such company is Pheedo (blog). Pheedo just keeps on keeping on.
We know that FeedBurner (blog) (API) offers ads in your RSS feed. But you then have to have your RSS feed "hosted" by their website. So if I placed ad in my RSS feed, I can no longer point to my own RSS feed, but I'd have to point to their copy of my feed on their website. Sucky.
Enter stage from left… Pheedo. Easy RSS Advertising From Pheedo. Now I can have ads in my own RSS. Yeah! That's nice. But what I'm really drawing your attention to is their blog and in particular the posts about the state of the RSS industry.
I've often linked to the fairly basic Technorati graphs showing the upward curve of the blogosphere see: Times they are a-changing… and Technorati – State of the blogosphere April 2006 and Technorati – State of the Blogosphere, February 2006.
But now Pheedo are sharing some of their own really excellent statistical research. Here are some excellent posts related to RSS-based advertising (CTR ratios, best placement, best frequency etc.):
Pheed Read #2 – Standalone RSS Ads Perform, Ad-to-Post Ratios Clarified
Standalone RSS ads are far more successful than inline ads.
A standalone RSS ad (the entire post is the advertisement) generates, on average, a 7.99% click-through rate – over nine times more clicks than an inline RSS ad (an advertisement within a publisher's post).When ads are placed in every other feed post, users clicked on the ad 3.24% of the time. This is over three times more effective than placing an advertisement in every post in a feed, where the CTR is 1.04%

"Pheed Read" No. 1 – report on the state of RSS advertising.
Tuesday is the most active day in RSS; Saturday least active.
The “morning scanners” view most content; late night readers click through more.
Pheed Read #1 was just the basic info, but Pheed Read #2 contains really valuable information. I find it quite rare the a company will publish truly useful stats with truly useful graphs. If you're into RSS-based advertising, you should DEFINITELY subscribe to the Pheedo blog.
(Found through SEOData using the reBlogger aggregation product)
Tracking the mood(s) of the blogosphere
April 27, 2006 — Mark WilsonWant to know the current moood of the blogosphere?

Ok, here are the details: it's updated every 10 minutes and it's not the whole blogosphere, it's only the 10 million LiveJournal bloggers. But still it's cool! Well done to MoodViews – Tools for Blog Mood Analysis.
Read more about it. An excerpt:
Software that tracks mood swings across the 'blogosphere' and pinpoints the events behind them could provide more insightful ways to search and analyse the web, researchers say. The software, called MoodViews, was created by Gilad Mishne and colleagues at Amsterdam University, The Netherlands. It tracks about 10 million blogs hosted by the US service LiveJournal. "I noticed that blog posts on LiveJournal have mood labels attached," Mishne says. "We started to collect this information and noticed trends in different moods over time."
Hmmm… but in the interview I recently did, I described something similar to Moodsignals. Before I get to that, let's first read a bit about Moodsignals:
On Valentine's Day, there is spike in the numbers of bloggers who use the labels "loved" or "flirty", but also an increase in the number who report feeling "lonely". The latest addition to Moodviews, a program called Moodsignals, tries to explain match these blogospheric mood swings to current events. It identifies emotional peaks by comparing recent label usage with records of previous use. When it finds a spike, the program picks out less commonly used words from relevant blog posts in an effort to identify the cause of the emotional change.
Here is the "loved" Moodsignal in the month of February (valentines day):

Check out their various services:
- Moodgrapher tracks the global mood levels,
- Moodteller predicts them, and
- Moodsignals helps in understanding the underlying reasons for mood changes.
- Moodspotter coming soon
- Moodfeeds coming soon
- Moodstickers put your mood on your website – pretty cool
In my interview about reBlogger I described the usefulness of tracking the employee blogs for a competing company:
Mark Wilson: For example, the Chief Technology Officer at Microsoft, he has a problem at the moment: he's got 27.000 employees and I don't know what percentage of them blog, but the OPML file for Microsoft is HUGE. So they have an enormous number of people blogging. Now the CTO of Microsoft cannot possibly read all of those blogs everyday, so he needs something which is smart enough to capture into themes, perhaps positive comments or negative comments, and in this way he could follow what is happening in terms of the bloggers inside the company. Somebody else, like Bill Gates, might want to track graphically, with a graph, the growing number of interest in Ajax; he might want to track what people are saying about Live.com, or Microsoft Office, the Windows version vs. the web version. If you've got a script being used on any day you'd find a 100 different opinions, and there is somebody out there who wants to track those opinions, and watch them rise or fall.
That isn't my the Moodsignal idea, here it is…
Mark Wilson: Well my idea is this, let's say that you're doing market research and you're trying to figure out what your competitor's doing. So for example let's say Microsoft is trying to understand what any competitor is doing, if you were to collect all their blogs, and you were to analyze them for upcoming themes…so say Microsoft wanted to follow the performance of a product such as Flex, a new product from Macromedia. Now, I'm just guessing this, but because companies try to encourage employees to blog in advance of a product coming up, I'm willing to bet that if you mapped out the number of posts in a particular team, say the Flex team, there would be a spike in the number of posts while they're developing their new version, and then there would be a spike just before launch the new version. So I'm guessing we haven't built the software to test this, but I'm guessing that if we mapped against product launches, and if we mapped the number of posts that that team, if we could figure out who was on that team, if we could map the two we would see a correlation. So, it's a possibility for market research all sorts of things.
Check out the rest of the interview with me.
It would be pretty cool to see some kind of Technorati style overview of the blogosphere containing moods or something useful, kinda like Technorati makes their graphs public every few months… like this one:

I'm just day dreaming here… but if they had an API and encouraged mashups and mashing of their data… wooo! My mind boggles with possibilities. I could extend reBlogger to include their API and overlay their data on top of the stuff we generate for customers.
BUT they would need to extend beyond just tracking LiveJournal. And they can't just collect the moods that LiveJournal generate, they will have to evaluate the mood of blog posts themselves. That's a fair amount of work.
I'm convinced that corporates will find this useful.
Sphere… of influence
April 27, 2006 — Mark WilsonHeads up! So what is Sphere? And what is so much better about it?
Sphere works better than other blog search I've seen, plain and simple…. when a Searchblog author goes off topic and rants about, say, Jet Blue, that that author's rant will probably not rank as high for "Jet Blue" as would a reputable blogger who regularly writes about travel, even if that Searchblog author has a lot of high-PageRank links into his site.
Think Blog Rank, Instead of Google’s Page Rank. The company has also taken a few steps to out-smart the spammers, and tend to push what seems like spam-blog way down the page. Not censuring but bringing up relevant content first. They have pronoun checker. Too many I’s could mean a personal blog, with less focused information.
Sphere is a new blog search engine that quite frankly blows everything, and I mean everything, I’ve seen out of the water in terms of relevance. Until now, no one has come up with a way to properly sort blog posts by relevance, and the general default way of showing results is “reverse-chrono”, which simply puts the newest stuff at the top. Sphere appears to have solved the problem, or at least taken big steps in the right direction. Their approach involves three key algorithms – an analysis of links into and out of a blog, an analysis of metadata around a post (links, post frequency, length of posts, etc.), and something Tony calls their “secret sauce”, which is content semantic analysis to filter out spam and to understand what a blog post is talking about. Result sets show only two posts per blog on the first page, so no one blog can dominate a category…

Their technology seems far more splog (spam blog) resistant than many of the other engines. They don't actively filter it out, but the spam blogs end up being ranked so low that you rarely encounter them. That sounds like the right approach to me.

BusinessWeek's Stephen Baker interviews Tony Conrad and Mary Hodder (mp3 audio / podcast)
Looks interesting. 🙂 FWIW: I found this through SEOData Blogosphere keyword.
UPDATE:
GCalendar + GMail + Search = new functionality!
April 24, 2006 — Mark WilsonSo you've seen GMail and Google Talk (IM) being integrated which resulted in Google Talk being placed right there in your GMail. That was ok. Nothing terribly new or innovative though.
Now try this:
- sign up for GCalendar and wait a few days (for the new menu bar to pop up in the top left of your GMail window). The two are now connected.
- Now send yourself an email (to GMail) in which you invite yourself to dinner tomorrow night. Read that email in GMail.
- Notice the "Add to calendar" offer on the right to automatically add an event to your GCalendar based on the invitation in the email? Notice that it has "read" your email and correctly identified your details, the date and time. Cool huh?

It's thanks to GMail being integrated with GCalendar.
Think about that for a moment. How did it know that the email contained an invitation to dinner, the day and the time? The natural language ability of the Google search engine is being integrated into the other apps.
They appear to have a remarkable ability to understand commonly spoken language, if they can "read" that the email is an invitation and can correctly pick the event, the day and time and offer to add it to GCalendar.
What if they keep doing this right across all their applications? I just blogged about Office 2.0 in prepration for this post, because this is where the action really happens. Those Office 2.0 applications all stand alone and don't integrate (think MS Office or Open Office). But further than that, they have no hope of replicating Google's ability to understand natural language either, so they won't be able to compete with the functionality that Google provides.
I'm suggesting that Google will integrate their technologies in really useful ways BECAUSE they can understand natural language so well. The upcoming WinFS wanted us users to "mark up" our documents so computers can understand the contents of the documents, but Google Desktop forged ahead and learned to understand our documents – not needing us to mark them up. Natural language came to market first – and WinFS got canned.
The only remaining two questions are:
- When will GOffice arrive and what will the integration be like?
- Will Microsoft be able to integrate their natural language stuff (if they have any) into their Office Live stuff?
I'd like to hear your thoughts and ideas.
Office 2.0 (as in Web 2.0)
April 24, 2006 — Mark WilsonWeb 2.0? Yawn. Office 2.0 will be a good fight to watch. The space is growing so rapidly. The number of potential customers is enormous. The need is there. The technology is there.
UPDATE: The Next Wave in Productivity Tools – Web Office extremely good and detailed article on the next generation!
Why Google is extending RSS
April 24, 2006 — Mark WilsonInteresting…
"GData combines common XML-based syndication formats (Atom and RSS) with a feed-publishing system based on the Atom publishing protocol, plus some extensions for handling queries."
So GData is a new protocol, but "based on Atom 1.0 and RSS 2.0." Actually at first glance it seems to be a mix of RSS and APIs
Some links: Why Google is extending RSS, GData – Google's new syndication protocol, a description
What do you think?
Times they are a-changing…
April 24, 2006 — Mark WilsonHere are some highlights that you may be interested in:
Technorati Top 100 Is Changing Radically:
There are many implications to this phenomenon, all of them fascinating and deeply disruptive to U.S. West Cost-centric view of the blogosphere:
– Blogging is a global phenomenon – duh! (I can’t even read a lot of the blogs that link to Publishing 2.0)
– MSN Spaces is kicking MySpace’s butt in Asia
– The cross-linking power of these personal blogs makes those of us writing on “professional” topics look like we’re sitting in a very small room
– The technology blogs that dominated the early geekosphere my soon be crowded out of the Technorati Top 100
– The provincial U.S. view of 2.0 does little to help us understand the globalization of 2.0
Would you like a blog with your phone?
April 21, 2006 — Mark WilsonYou may have read this article: Can Bloggers Make Money? If you haven't then take a moment to scan it and get the feeling of their question and their answers.
In reply Dave Winer wrote:
… It's as if they asked how many miles per gallon of oats a car gets, a few years after horseless carriages came along. The question doesn't even make sense. A person with a blog is analogous to a source in the old publishing world. Sources don't get paid directly …
Dave's software approaches blogging from a slightly different perspective. For example if you look at his page, his thoughts are just that – thoughts. His blog is his own personal expression. Every day is simply a series of short self-expressions.
The reason he doesn't think of blogging as a source of revenue is simply… his revenue doesn't NEED to come from his blogs (advertising), he has a business on the side doing that.
Let's pop over to wikipedia for a moment and find out a bit about where "blogs" came from.
The term "weblog" was coined by Jorn Barger on 17 December 1997. The short form, "blog," was coined by Peter Merholz. He broke the word weblog into the phrase "we blog" in the sidebar of his weblog in April or May of 1999.
Dave Winer is one of the pioneers of the tools that make blogs, he has also been involved in podcasting and RSS. I am interested in Dave's perspective because he has been involved for so long and has such a mature and long term view on things.
It says a lot about Dave that he doesn't plug his business (much) and doesn't even have adverts on his wildly popular blog to promo his business. Why? Because Dave seems to see a blog as personal expression. That makes sense of his comment that companies are masquerading magazines as blogs. He seems to think that the whole self-expression thing will only continue mushrooming until the way people express themselves and the interaction between people is remarkably different… which is his point about the uselessness of asking how many gallon of oats a car gets.
Will there be a huge increase? Yes, for sure. I look forward to when WordPress is on my XDA II Mini and I can blog thoughts throughout the day – at random and on a whim. That's when Dave's vision really happens – when we (2 billion phone users) can blog at any time, in a movie or on a date. Blogs will then be used as dashboards, whiteboards, note takers, reminders and who knows what else. With the microcontent and structured blogging things happening, the data I blog can be shown in different and more suitable visual formats. If I blog a calendar event, it displays in a calendar. If I blog a note, it looks and behaves like a note.
And meantime a lot of blogs will be for-money (magazines masquerading as blogs). That will always be the case.But when you get a blog with your phone (pre-installed) then there will be ENORMOUS economies of scale and I have no idea where that will go and what will happen at that time. But it's certainly an interesting development.
NOTE: When this happens WordPress will need to change the blog format. We can't have a huge heading and new page and trackbacks for each and every thought. This is another difference between Dave's design and the rest of the blog software out there.
UPDATE: Matt, the co-creator and co-owner of WordPress has a blog and he has the exact feature I noticed on scripting.com – the ability to hide the heading text and all the "extra" information that readers really don't want to see. On his blog you just see the content. If you want the extra info, you open the permalink and then you get to see the full layout.
Digg-In-A-Box… the interview
April 20, 2006 — Mark WilsonIn a previous post reBlogger past, present and future I mentioned that I had completed our first interview about reBlogger with Robin Good. I'm very pleased to point to the interview (available as audio, MP3 and text): Digg-In-A-Box? Automatic News Filtering And Aggregation? Newsmastering Engines Keep Growing: reBlogger Is Next
Here is a short quotation from the page containing the 40 minute interview. Robin says:
There is a huge, infinite market for quality, filtered information on specialized topics out there.
Why?
Because, everyone on the edge of using new media technologies today knows that the amount of information that is ALREADY coming our way now, it is just too much to handle. Tech Memeorandum, Digg, Personalized Google News, Start/Live are great, but they are only a small part of the solution.
We just need to scale up more. And that means doing ourselves the dirty work of filtering, selecting and aggregating the very best content out there on any specific imaginable topic. This is why, this is truly the job of the future, and watching only blogs, as they are today, maybe a too limiting view.
And when we say aggregate it should not mean just to aggregate blog posts, but also and evidently news, comments, video and audio clips, relevant products and services and relevant ads and commercial info on that very content theme.
And what tools do we have today to do this kind of work?
Few. In fact too few to really satisfy the soon to explode demand for these kind of publishing services that the content market will see.
And this is why I took the time to skype up Mark Wilson, CEO and founder of one of those very few, but also very promising companies already moving its early steps into this soon-to-be-blooming newsmastering industry.
reBlogger a server-based software that Mark and his team have released over a year and half ago, is a newsmastering engine that allows the creation of highly thematic and relevant newsfeeds on just about any selected topics of interest. You feed the engine with enough news sources in the format of RSS/Atom feeds and then you specify the "themes" or topics you want to be output. reBlogger does the rest.
Not only.
As you can learn by reading through, Mark and his team are working right now on the upcoming release of a full "Digg-in-a-box" type of tool, which allow any online publisher to recreate the popular and highly effective Digg-functionality on their sites to create their vertical information portals fueled by their readers.
Here, for example, is a good example of what reBlogger could do, if you wanted to build a site about the upcoming World Soccer Cup in Germany.
Read or listen to the mp3 online: Digg-In-A-Box? Automatic News Filtering And Aggregation? Newsmastering Engines Keep Growing: reBlogger Is Next
Technorati – State of the blogosphere April 2006
April 19, 2006 — Mark WilsonThis just in!
… the blogosphere continues to grow at a quickening pace. Technorati currently tracks 35.3 Million weblogs, and the blogosphere we track continues to double about every 6 months, as the chart below shows…
More mashup madness – Flikr spelling
April 19, 2006 — Mark WilsonFrom Spell with Flikr comes…
What is this? Spell with Flickr is a small program that lets you type in whatever you want, then goes to flickr and grabs pictures for each an every letter! It also allows you to change the images that you see, so you can find better images for your word or phrase!
Here is our product name reBlogger:









My name (Mark):




This is really fun, give it a try!
Analysis of comments threshold and post voting
April 12, 2006 — Mark WilsonI have written quite a bit on meme sites and UGC (User Generated Content). You may also have noticed I am fascinated by the Slashdot vs DIGG comparison.
Below is a typical layout of reBlogger posts for a given day. It's not inspiring. But that's ok, we were targetting SEO companies who are not focussed on the user experience (ajax, voting etc.)
But as we prepare the user-theme-website reBlogger (a tool to build meme/DIGG websites) which is under-construction here and here I am exploring more and more in this blog the ideas surrounding relevancy, user-generated content, user-interaction, community involvement, exploration, semantic web, tags, research and user-context and blog-post-context (and trying to match them).
In this post I am exploring thresholds and voting. First let's look at some leading examples of each.
Haven't we figured out that the crowd is generally smarter than any one individual in the crowd? – Jeremy Zawdony
Here is a screenshot of Slashdot style "below threshold" ranking of items. The users get to vote on what is useful and what is not… but it's for comments on posts. For anyone who has tried to read the MASSES and MASSES of comments on a slashdot post, this threshold stuff is invaluable.

DIGG implemented a "below threshold" concept in their system too… but it's also for comments only.

So thresholds work well for a big flow of comments. Yay. But when you have an enormous flow of posts, could we also use this threshold concept?
Of course in terms of matching my user-context and the context of the voter, if a visitor votes down any post covering a team they don't like – that should not affect my view if I like that team! Sigh. So I really should only see the effect of votes from people who have similar keywords to mine. They like the same things as me, and therefore their votes are far more likely to be relevant.
Below is my very unattractive rendition of what user-voting combined with thresholds could do for blog posts. If you add in changing background colors to highlight the items that match their selected keywords – then a visitor can FAR more easily scan a page to view items that match their keywords and are voted hot by visitors who perhaps have more time on their hands to read and vote on everything! 🙂

In my imagination I could visit the World Cup 2006 site and quickly scan for hot stories that match my interests (south african or australian teams).
It would be great if unread items were bolded and read items weren't. Heh. CSS already does that. Woohoo.
OK, I user-tested this with Joel. He didn't get it. Let me try again. 🙂
Below is a typical reBlogger page on TopXML – in amongst all those posts, some are clearly better than others. How do I (a reader who is interested in the topic) determine which item to read and which to skip?
Enter stage from left: thresholding.
In this page we have hidden the items which other users have voted down, or (inversely) which have not been voted up. Now only the really good stuff is displaying and I can get to the other items if I want to.

I added three extra goodies in the picture above:
- faded background highlighting to draw the eye to the hidden info
- if some of the voted-down posts contain my keywords I have specified that I am interested in, I am notified
- I inserted a star in the top most post, to somehow indicate that this post is truly a winner. We have all seen these kinds of posts, they are just head and shoulders above the rest. They should get a star, so when I view the page I can immediately click on that post with the certainty that I will see a cracking-hot post.
One concern is: because this is ordered by date (not by vote) the newest posts will always have a vote of 0, and I guess 0 should be above the threshold? But that kinda defeats the idea of hiding the complexity. Sigh. Hmmm… some users will want a threshold that includes 0 (view all new items) and some will want 1, 2 or 3 or whatever. Some may even want to view all – including viewing negatively rated items.
Some sites also use grouping of similar topics… but we aren't doing that yet. Here are some examples of that.
Cloudee (below) groups similar posts, but doesn't have voting + thresholds

The ever-wonderful Chuquet (below) also groups items and handles information overload by hiding it all and saying "(45 linking articles in the last week…)" and giving a link to all of the items. Quite effective! They don't provide voting.

I see that everyone thinks that thresholds is for commenting and voting is the way to solve information overload for posts – but I think that voting can result in thresholds for posts – it's the ideal way to sort the wheat from the chaff in blog posts.
Ivan codes more reBlogger engine goodies
April 11, 2006 — Mark WilsonIvan has had a hard day coding the next generation engine. I definitely see the wisdom of separating reBlogger 3.2 (and 3.3) from this product.
- RB 3.x is really for SEO sites and is easily built and installed, minimal fuss
- Our next generation product is for creating DIGG sites – it's got much more power and ability
The two code bases should remain separate I think. They serve different customers. The people now buying reBlogger 3.2 will not necessarily like the enterprise features of this next generation product. I see the two product this way:
- reBlogger is SEO-in-a-box. It's for existing businesses and websites to bulk-up and improve their ranking to sell existing products.
- Our next generation product is a business all in itself. It's DIGG in a box. One day you had no company and no income, the next day you have a good shot at leading the DIGG pack and making real money.
That's IMO the vast difference between the two products. We probably need to invest 3-6 months into our next gen product until it's really kick-butt, but that's the enormous difference I see emerging.
Rolling a DIGG style website
April 10, 2006 — Mark WilsonMy post on Collections of 2.0 posts remains by far the most popular post in this blog. Here is a list of 80 DIGG-style websites "Digg's Friends and Relations".
Another interesting blog post is Web 2.0 Commoditization. Commoditization is where so many people are building widgets that someone eventually builds a widget-making-tool to help everyone build their widgets easier. reBlogger is that kind of product, it helps you make DIGG-style websites easily.
How many people are into this social media industry? I've listed some Technorati stats before, but here is an interesting post about the money in the industry: Social Media Spending to Hit $757M in 2010.
As I mentioned previously reBlogger has a bunch of SEO features, but it's also designed to create DIGG-style websites. Let me explain.
 Do you want to make a DIGG-style website?
Do you want to make a DIGG-style website?
 If you did, would you build a tech site like a Kicks website?
If you did, would you build a tech site like a Kicks website?
 Perhaps you're pink and cuddly… then maybe you'd build a Bringr website!
Perhaps you're pink and cuddly… then maybe you'd build a Bringr website!
Whatever you want to build, you can use reBlogger to build it.
Take a look at Ivan's Coding reBlogger blog as he describes his experiences of building on top of reBlogger. He is building a DIGG-style website in only 10 days.
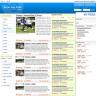 So what does a reBlogger based DIGG style website look like? Check out the preview image and watch his DIGG-style Football World Cup 2006 site as it grows!
So what does a reBlogger based DIGG style website look like? Check out the preview image and watch his DIGG-style Football World Cup 2006 site as it grows!
We'll no doubt package these extensions Ivan is building, so that people don't have to build it for themselves. The idea is that customers just buy reBlogger and then make their own look and feel. Insta-DIGG! 🙂
After building this Football World Cup 2006 site I'd like to see us build another one on another topic. I know where the Microsoft OPML file is which contains ALL their bloggers. hehehe. And IBM has one too (one for their products, one for their bloggers). Muhahahaha. What could we do with those?
For the future… I'd like reBlogger grow a bit in the ability to maintain these different themes. One set of data, but when a person views a Football post, they view it with the appropriate look and feel. If they view a Microsoft post, they get that look and feel. If they view an IBM or SEO or whatever post, they get that specific theme. Why should EVERY page on the website look identical to EVERY OTHER page? Booooring!
So when we move on to the next theme, I want this football theme stored, I want to be able to view it's "front page" and still see it's categories etc. I don't want to discontinue this theme, but let people look back over all the themes we've had in the past. Since most of our look and feel is in CSS, I think this should be relatively simple.
SEOData gets a facelift
April 10, 2006 — Mark WilsonSEOData has had a facelift! Let us know your feedback.
What is SEOData? It's the flagship website for reBlogger wrt SEO customers. We explain how to use reBlogger when you have SEO needs.
reBlogger.com is our flagship website (currently under construction) for theme (or digg) oriented customers. We demonstrate how to use reBlogger as a development platform to build you own digg–style website with voting and more. Read Coding reBlogger to follow it's development. The current project is to show how reBlogger can be used to build a Football World Cup 2006 DIGG site – in only 10 days! What would YOU do with your reBlogger?
reBlogger – it's many things to many people! 😀
reBlogger – Release notes page
April 7, 2006 — Mark WilsonWe have created a page that now outlines the improvements that Joel makes to reBlogger on an ongoing basis. Say hello to… the reBlogger release notes page! It helps customers understand why we go through versions so quickly (because we're adding features all the time!) 🙂
Joel is also documenting the next release as he writes it with a COMING SOON! section at the top. Be excited. Be very excited.
Upgrade instructions are also included with the release. Because we include the site and administration HTML in the DLL (the engine), quite often you will only have to upgrade the DLL to get the new functionality. No fiddling with HTML in ASPX pages. Yay!
Technorati – State of the Blogosphere, February 2006
April 6, 2006 — Mark WilsonTaken from the superb Technorati blog. Please read the full details for yourself.
- State of the Blogosphere, February 2006 Part 1: On Blogosphere Growth
- State of the Blogosphere, February 2006 Part 2: Beyond Search
Ok I know this is old news. I know. But I want it recorded here so that we can look back on it. 🙂
Half of all blogs actively use tagging!

1.2 million posts per day and 50,000 per hour!

2.7 million bloggers update their blogs at least weekly

Technorati currently tracks 27.2 million weblogs, and the blogosphere we track continues to double about every 5.5 months

People are still paying a lot of attention to mainstream media stalwarts like The New York Times, CNN, and The Washington Post but here come the bloggers.

Technorati summary:
- Technorati now tracks over 27.2 Million blogs
- The blogosphere is doubling in size every 5 and a half months
- It is now over 60 times bigger than it was 3 years ago
- On average, a new weblog is created every second of every day
- 13.7 million bloggers are still posting 3 months after their blogs are created
- Spings (Spam Pings) can sometimes account for as much as 60% of the total daily pings Technorati receives
- Sophisticated spam management tools eliminate the spings and find that about 9% of new blogs are spam or machine generated
- Technorati tracks about 1.2 million new blog posts each day, about 50,000 per hour
- Over 81 million posts with tags since January 2005, increasing by 400,000 per day
- Blog Finder has over 850,000 blogs, and over 2,500 popular categories have attracted a critical mass of topical bloggers
The 2.0 shakeout – lessons from GE on surviving
April 6, 2006 — Mark WilsonI've written several times about moving up the tree, no longer eating the low hanging fruit. Almost everything we currently call 2.0 is low hanging fruit. A shake-out is looming for sure.
How does this company of ours survive it? To look forward let's first look back.
Remember the .com boom? Everyone (and his dog) had a website and was doing some ecommerce. A shake-out was inevitable because anyone (literally) could install a web editor (or use GEOCities) and make a site. Anyone could sell at zshops at Amazon or Yahoo smallbusiness stores or many many other options. With a small bit of javascript I "monetized" my TopXML website by selling training CDs. Anyone could do it.
And it got easier and easier for anyone to do. This article "The Earth's learning curve" discusses the same event, which they call diffusion of knowledge, in the sphere of science.
Put simply, human beings were getting smarter … If the rise of science marks the first great trend in this story, the second is its diffusion … This diffusion of knowledge accelerated dramatically in recent decades … The diffusion of knowledge is the dominant trend of our time and goes well beyond the purely scientific
They state that with the advent of science 300 years ago and the diffusion of knowledge across the earth and into more and more people's lives and homes (I have 3 different types of discovery channel at home!) that people stopped trying to work out where they fit into the world and we began to figure out how to change the world to suit our needs.
Humans were no longer searching for ways simply to fit into a natural or divine order, they were seeking to change it.
The same thing is happening on the internet. Diffusion of IT-related knowledge has been accelerating exponentially. With talent, Javascript, Ajax, VS.NET (or Eclipse), a good team of similarly talented people and a lot of determination you can join the growing throng of 2.0 "me too" websites scrambling to make a living.
So what happened with the dotcom boom is happening again. And the choke point remains – what stands between you and success is: getting traffic and monetizing it.
What have we figured out so far?
- Everyone can build 2.0 applications because the tools are free or cheap and skills are common
- The dotcom boom was followed by a bust/shakeout and only the ones which actually made money managed to survive (usually those who have done more than just one narrow thing – Yahoo, Amazon, Microsoft)
- Although monetising gets easier, actually making money gets harder as more people enter into the fight for resources/revenue. Only the ones who make money actually survive or get bought out.
So where does this leave us? What's the solution? I once heard an interesting comment – I have found a useful quote on a webpage which is pretty similar to what I heard many years ago:
It's important for you to remember something about gold rushes. The people that make money in the gold rushes are not necessarily the people who are looking for the gold. The people that make money in the gold rushes are the ones selling the picks and shovels and tents to the other people who are looking for the gold.
You can read more about that here in Vinton Cerf's keynote speach about telecommunications and the internet.
Please take a moment to read Dreaming sessions By Jeff Immelt. You probably know Jeff is CEO of General Electric. That is a great article with a silly name. Someone did great research and a fab interview and was forced to hype the article. Anyway. Moving on. The key thing we can learn is this:
We've been in the diesel-locomotive business for about 90 years. We have deep relationships with the major U.S. railroads, and increasingly with foreign railroads, too. Those companies would like to do a better job of computer-aided dispatching, to know when a locomotive has been shut down for a long time and to figure out how they can get it into more productive service. So it was natural for us to get into rail-information technology. … And it comes not from golly-gee-whiz innovation, but from a whole new business that came to us from solving traditional customers' problems.
There you have it. They are shifting from making railroads into helping other railroad companies make money. Clever. They collect the knowledge of others and massage it, flip it, organize it and sell it back to them. You've probably heard of The knowledge economy – from the awesome wikipedia:
a knowledge-based economy is a phrase that refers to the use of knowledge to produce economic benefits. The phrase was popularised if not invented by Peter Drucker
That is profound. That's the change in GE. It's what reBlogger is good at – collecting knowledge to produce economic opportunity for our company and especially for our customers!
BillG sees the same shift in the use of knowledge has occured. In his article for Newsweek he says:
It's hard to say exactly when it happened, but at some point in the last 20 years the word "knowledge" became an adjective.
The rest of the article is fluff, but that point is profound to me. Here is a more in-depth consideration of the english language perspective of the whole knowledge is an adjective thing (it's non-essential to this discussion).
Access to knowledge is essential #1: When Googling became a verb "to google" or "i googled it" then it was clear the search engines had arrived and were now a significant part of everyone's life. Everyone wanted to access knowledge.
An ability to find and retrieve knowledge is essential #2: A few days ago a father said to me that he would have to get a PC in his home (which he didn't want) because his kid needed it for school homework. If the father doesn't allow the internet (with it's dangers and rubbish) into his home, the child can't do his homework. Wow. Access to knowledge is therefore essential to growing up.
Regardless of if knowledge indeed is now an adjective – I agree that things are changing. Access to knowledge is very important and the ability to manipulate knowledge is crucial for businesses. As Jeff said the key is "not from golly-gee-whiz innovation". Golly-gee-whiz innovation in our industry would be things like CSS, a cool name/url, Ajax or a new framework library. That's where the current competition is at, but that's not what it will take to survive.
So how does a company survive? What change is required? The way to survive when there are literally hundreds and hundreds of competitors is – not to have even better Ajax tricks, not to have cooler CSS! Why not? Because everyone can go view > source and have it for themselves within minutes. That's the low hanging fruit. We need to look higher up the tree for food.
As Jeff moved GE into rail-information technology and solving traditional customers' problems, we must consider what our equivalent is to that. Here's what we're not going to build:
- another corporate blogging system,
- another meme website,
- another DIGG clone,
- another bookmarking website,
- another feed-markup service
This is a short list of the enormous number of different types of rail road companies, the miners.
We need to solve their problems. What problems do they have? If we just look at corporate blogs, their major problem (and our opportunity) is to help the business owners to track, collate and research their employee blogs and
In summary, what advice have we collected so far?
- Move up the tree, eat higher fruit – the harder to reach "knowledge" stuff
- Make tools that others use and will pay for (not free stuff unless it's a loss leader)
- Make actual money, not just build coolness factors
So we finally come to this business of ours. Where can we go from here to survive the shakeout that will inevitably come after the big buyouts?
- reBlogger should become a value added (marketing/research/management) application. We need to understand what metrics companies will be looking for. This is like the GE-railroad companies approach above.
- reBlogger.com that we are building is a me-too idea which is going to compete directly against the coolness of the other 2.0 sites – unless we have something significant in mind that will drive sales, we should look long and hard at this. Any idea we innovate will rapidly be copied by the hundreds of others out there.
- We can build a crawler and selling the combined data as a service to the hundreds of 2.0 companies out there. This is like the building tools approach above.
Feedo Style 2.0 logo
April 5, 2006 — Mark Wilson You gotta love it. So 2.0! Feedo Style.
You gotta love it. So 2.0! Feedo Style.
They take feeds from anywhere (even from other syndication services) and mark them up so the feed looks like a vertical ticker or is animated in some way. Clever.
reBlogger can learn from this for sure.
(More) things I’d like to see on WordPress.com
April 5, 2006 — Mark WilsonThis is a follow up to my previous post: WordPress(.com) suggestions
5 April 2006
What emoticons does this support? I see 🙂 😀 😦 😉 but what else? What if I just insert all the Yahoo ones here and see which show up and which don't?!
😛 :)) ![]() :-O 😡 :"> :-> B-) ;;) :-* :-S >:D< =(( #:-S =)) /:) 😐 :(( O:-) :-B =; I-) 8-| L-) :-& :-$ [-( :o) 8-} <:-P (:| =P~ 😕 #-o =D> :-SS @-) :^O :-w :-< >:P <):) :)] :-c ~x( :-h :-t 8->
:-O 😡 :"> :-> B-) ;;) :-* :-S >:D< =(( #:-S =)) /:) 😐 :(( O:-) :-B =; I-) 8-| L-) :-& :-$ [-( :o) 8-} <:-P (:| =P~ 😕 #-o =D> :-SS @-) :^O :-w :-< >:P <):) :)] :-c ~x( :-h :-t 8->
Why oh why does the editor insert BR's where there should be /P and why oh why do I keep having to re-edit what I have already edited to remove the whitespace between paragraphs. Ugh.
Why oh why do some themes strip my italics, others strip bold. I can then go back in an add it again and it's not stripped. Maybe it sees me adding it for a second time and realizes that I really want it in there and then leaves it. Or maybe the saving and editing are different scripts, the one strips and the other doesn't? Nah. It realizes.
The editor won't let me insert HR or H2. Where is the emoticon for pulling hair out. 🙂
(I love WordPress.com BTW. Really! I chose to host here. I like it. This is empassioned feedback. I love the handheld/PDA layout, I love the themes, I love the way it handles things like pinging technorati etc., I love how it handles images and thumbnails. Go WordPress!)
Make the comments for posts differentiate between readers comment, my comments to readers and pingback. Kinda like this, take a look at the visual layout of their comments. Nice. 😀
Forward, backward, first and last navigation on the post pages please. Do you know how hard it is for a reader to move to the first post?
